[컴][Hack] 해킹툴
Tools
- http://www.ollydbg.de/ : 올리디버거(참고)
- https://github.com/x64dbg/x64dbg: x64dbg
- https://github.com/HarmJ0y/pylnker : windows .lnk 를 분석할때
[컴] cpu가 그래픽처리를 위해 GPU를 사용하는 과정
그래픽카드와 함께 CPU 가 좋아야 하는 이유
내용에 틀린부분이 있을 수 있다. 그러니 의심이 가면 관련 부분을 찾아보기 바란다.일단 단순하게 표현하면, 던전으로 들어가기 전과 후의 장면은 크게 달라진다. 그런데 캐릭터가 던전으로 들어갔는지, 아니면 그 앞까지 왔는지를 결정하는 것은 graphic 부분이 아닌 다른 code 부분이다. GPU 가 graphic 부분의 일을 처리하겠지만, 그 이외의 logic 을 계산하는 것은 cpu 이다. 그러므로 cpu 가 느리다면, 결국 gpu 가 아무리 빨라도 끊김(흔히 버벅임)을 방지하기는 어렵다.
cpu가 그래픽처리를 위해 GPU를 사용하는 과정
The_CUDA_Handbook.pdf 에서 좋은 설명을 확인할 수 있다. 여기선 일부를 정리해 놓았다.
cpu 와 bus
현재까지, 보드의 south bridge가 대부분의 주변기기들을 담당하고, north bridge 가 memory controller 를 가지고 있다. 그래서 이 north bridge 의 memory controller 를 이용해서 cpu 는 memory 와 통신한다.(이 통신이 이뤄지는 interface 가 front-side bus 이다.)
그리고 north bridge 는 gpu 와 PCI Express interface 를 이용해서 통신한다.(물론 pci express 이전에는 AGP 같은 것이 있었다.)
gpu 안에는 gpu memory controller 가 들어가 있다. 그래서 이 memory controller 를 통해 gpu memory 와 통신한다.
Memory controller 가 CPU 안으로
이러다가 cpu 가 memory controller 를 내장했다.(AMD의 Opteron 과 Intel의 Nehalem (i7) ) 그래서 north bridge 없이 바로 memory 와 통신하게 된다.
그리고 I/O Hub 를 통해 PCI express interface 를 사용해서 GPU 에 접근한다.
그리고 I/O Hub 를 통해 PCI express interface 를 사용해서 GPU 에 접근한다.
 |
| The_CUDA_Handbook.pdf 의 2.1 |
HyperTransport (HT) / QuickPath Interconnect (QPI) interface
이 상황에서 cpu 를 여러개 사용하기 위해 cpu 간의 통신이 필요했다.(Multiple CPUs (NUMA)) 그래서 생긴것이 HyperTransport (HT) / QuickPath Interconnect (QPI) 이다. 이 interface 로 cpu core 끼리의 통신과 cpu 와 I/O hub 와의 통신을 하게 된다.
- cpu core <---> cpu core
- cpu <---> I/O hub
I/O hub 가 CPU 안으로
인텔의 Sandy Bridge 부터 I/O hub 를 cpu 안에 내장하게 된다.

CPU/GPU 연동
The_CUDA_Handbook.pdf 의 2.5 부분의 내용이다.
GPU 는 직접적으로 page-lock 된 CPU memory 에 DMA 를 통해 접근할 수 있다.
Page-locking 은 주변 하드웨어가 CPU Memory 에 직접적으로 접근할 수 있도록 해주기 위해 OS가 사용하는 기능이다.
locked page 들은 OS 에 의해 퇴출(eviction) 에 적합하지 않다고 표시된 상태이다. 그래서 device driver들은 이 주변기기들이 메모리에 직접적으로 접근하기 위해 페이지들의 물리적인 주소들을 이용하라고 프로그램할 수 있다.
CPU 는 여전히 불확실한 상태에서 memory 에 접근할 수 있다. 그러나 메모리는 옮겨지거나, disk 로 paged out 되지 않는다.
DMA 는 GPU 가 CPU memory 를 "cpu 의 실행"에 대해 독립적으로 그리고 병력적으로 read/write 할 수 있게 해줬다. 다만 여기선 race condition 들을 피하기 위해 CPU 와 GPU 사이의 싱크를 맞추는 것을 고려해야 한다.
- Pinned host memory(pinned buffer): GPU 가 직접 접근할 수 있는 CPU memory 부분
- Command buffers: GPU 실행을 통제하기 위해 CUDA driver 에 의해 write되고, GPU에 의해 read 되는 buffer.
pinned buffer
pinned buffer 는 direct access 를 위해 GUP 에 의해 mapping 된다. CUDA 에서는 API cudaMallocHost() 를 통해 allocate 할 수 있다.
pinned buffer 가 주로 사용되는 방법중 하나는 GPU 에 command 를 보내는 용도이다. CPU 가 command 를 buffer 에 write 하고, 동시에 이것을 GPU 가 이전에 write된 command 를 read 하고 execute 한다.
이 buffer 의 앞부분(leading edge) 에 CPU 가 command 를 write 한다. 그래서 GPU 가 이때는 이 녀석을 읽을 수 없다.
GPU 는 buffer 의 끝부분(trailing edge) 에서부터 command 를 읽어드려서 실행한다.
이 command buffer 는 circular queue 라고 보면 된다. 그래서 한번 command 처리를 다한 부분은 다시 CPU 가 command 를 write 하기 위해 사용된다.
cpu-bound / gpu-bound
이 상황에서 2가지 case 가 있는데 CPU-bound 와 GPU-bound 다. bound 는 "경계" 의 뜻이니, CPU bound 는 CPU 가 경계가 되는 경우라고 보면 되고, GPU-bound 는 GPU 가 경계가 되는 것으로 보면 된다.
- 하나는 CPU 의 command 를 write < GPU 의 처리 속도(CPU-bound)
- 하나는 CPU 의 command 를 write > GPU 의 처리 속도(GPU-bound)
References
[컴][웹] Server-Side Event(SSE)
서버 사이드 이벤트 / 폴링 / 푸쉬 메시지 / notification / noti

Server-Side Event(SSE)
여기서는 ref. 2 에 있는 이야기의 일부를 다룬다. 되도록 ref. 2 내용 전체를 보는 것이 더 도움이 될 듯 하다.
대략적으로 이야기하면, 이녀석은 기본적으로 ajax 로 했던 polling 을 browser 가 대신해준다고 생각하면 된다. 즉, polling 을 사용했어야 하는 모든 경우에 사용할 수 있다. 그리고 polling 이 끊겼을때등에 대한 처리에 관한 설정(id 같은, ref. 2를 참고) 도 가능하기 때문에 훨씬 편리하고 좋다.
그리고 ref.2 에 보면 SSE 는 http protocol 로 만들어졌다고 한다. 그래서 이것을 실행하는 주체는 browser 안에서 layer 가 좀 다를 수는 있지만, js script 내에서 polling 을 구현한 것이랑 거의 다를 바가 없을 듯 하다. 여하튼 ref. 2 에서는 이것을 event streaming 이라고 부른다.
event streaming 을 close 하는 법
이렇게 주기적으로 browser 가 server로 부터 event 를 받아오는데, 이것을 close 하는 방법이 2가지 있다.
- 서버에서 close 하는 법 :
- Content-Type 이 text/event-stream 가 아닌 response 를 보내거나
- 200 이외의 HTTP status 를 보낸다.
- client 에서 close 하는 법
- source.close();
다만 이런 방법으로 Event streaming 을 끝내지 않고, 만약 network 가 끊어진 상황, 즉 browser 가 아예통신을 못하거나 한 상황에 의해 event streaming 이 끊긴 경우라면, browser 가 알아서 주기적으로 연결을 위해 시도를 한다.
message event
기본적으로 발생시키는 event 는 message event 이다. 하지만, server 의 응답에 "event" 를 정의해서 browser 로 하여금 새로운 event 를 발생시키도록 할 수 있다.
event: servertime data: The server time...
source.addEventListener('servertime', function(event) {
document.getElementById("result").innerHTML += event.data + "<br>";
});
Response
header 조건
- Content-Type: text/event-stream
- Cache-Control: no-cache
body
- data: data_you_want_to_put
data: The server time...
Security
보안상의 이슈로 client 에서 event handler 를 구현할 때 event 의 origin 을 check 하라고 한다.[ref. 2]source.addEventListener('message', function(e) {
if (e.origin != 'http://example.com') {
alert('Origin was not http://example.com');
return;
}
...
}, false);
References
[컴][하드웨어] GPU 의 memory bandwidth 와 VRAM
GPU 의 memory bandwidth 와 VRAM
다음은 ref. 1 의 "Memory Bandwidth, Memory Capacity" 부분을 의역한 내용이다.----
메모리 대역폭(memory bandwidth) 는 GPU 의 VRAM 에 한번에 얼마나 많은 양을 넣고(copy to), 뺄수(copy from) 있는 지를 알려준다. 당연한 이야기지만, 같은 해상도(resolution)에서 시각효과(visual effects) 가 많을 수록 더 높은 memory bandwidth 가 필요하다.(더 많은 data 를 한 번에 옮겨야 하니.)
VRAM 의 총용량은 GPU 의 다른 중요한 요소다. 필요한 VRAM 의 양이 현재 가능한 리소스를 넘어선다면, 게임은 계속 돌겠지만, 이 부족한 memory 부분만큼 CPU 의 main memory 를 이용하게 된다.
이것은 GPU 가 DRAM 에서 data 를 가져오게 돼서, GPU 의 VRAM 에서 가져오는 시간보다 더 오래 걸리게 된다. 결국 이것이 게임화면의 버벅임을 만들게 된다.
그래서 VRAM 의 양이 중요하긴 하지만, 일부 low-end 그래픽카드는 쓸데없이 VRAM 이 많은 경우가 있다. 즉, VRAM 이 부족해 지기 전에 다른 부분에서 bottleneck 이 걸릴 수가 있다. 그러므로 이런 경우를 방지하기 위해 benchmark 결과등을 잘 살펴서 구매를 할 필요가 있다.
---
Memory Bandwidth Specification
GPU 와 VRAM 간의 memory bandwidth 는 GDDR 의 spec. 을 확인해 보면 된다. GDDR6가 요즘 나오고 있다. 고대역폭을 위해 새롭게 만든 HBM(High bandwidth memory) 이라는 스펙도 있다. 이녀석은 GDDR6가 나오고는 경쟁력이 확실히 많이 떨어졌다.
GDDR6의 데이터 전송 속도는 최대 18Gbps로 고성능 GPU의 384비트 메모리 버스에선 864GB/s의 대역폭((18Gbps * 384bit )/ 8bit = 864GB/s)이 나온다.
- [분석] 차세대 메모리 집중탐구! HBM(High Bandwidth Memory) vs. GDDR5 > 배틀리뷰 - 하드웨어 배틀(Hardware Battle)
- HBM - 나무위키
- 18Gbps의 속도. GDDR6 메모리를 삼성/SK 하이닉스가 발표 - 컴퓨터 / 하드웨어 - 기글하드웨어
References
[컴][해킹] 해킹 공부 자료
지드라 / 기드라 /
해킹 공부 자료
- http://carpedm20.blogspot.com/2012/09/blog-post.html
- http://www.hackerschool.org/HS_Boards/zboard.php?id=Free_Board : 해커스쿨 자유게시판
- 해킹에 대한 간략한 이해
- 정찰, Reconnaissance
- https://hacker-tools.github.io/ : hacking 관련 수업 제목이 hacker-tools 이다.
- https://www.nsa.gov/resources/everyone/ghidra/
- Ghidra(기드라) : NSA의 Research Directorate 에서 만든 소프트웨어 리버스 엔지니어링 프레임워크
- 리뷰 | '소문 무성했던' NSA 리버스 엔지니어링 툴 '기드라' - CIO Korea, 2019-05-10
- Mateus Carmo M de F Barbosa / intro_x86-64 · GitLab : x86-64 assembler 예제들
- Linux Device Drivers, Third Edition [LWN.net]
분류
- Reversing
- System
- Network
- Web
- Forensics
- CTF
System
Buffer Overflow
- http://www.hackerschool.org/Sub_Html/HS_University/bof_1.html : 해커스쿨에서 만든 시리즈
[컴][HDD] Degaussing (디가우징) 이후에 HDD 를 재사용할 수 있나?
하드디스크 디가우징후 다시 하드를 사용할 수 있나? / 하드 재사용 / 디가우징 하드 재사용
요즘 디가우징(degaussing) 이 이슈이다. 그래서 관련해서 HDD 드라이브에 대해 좀 더 알아보기로 했다.
디가우징을 하면 데이터가 사라진다는 것은 알고 있다. 그럼 이 degaussing 을 한 HDD 를 다시 사용할 수 있을까??
그럼 이 servo sector 가 무엇이길래 이것에 따라 HDD 를 다시 사용할 수 있기도 하고 없기도 할까?
HDD 는 아래와 같이 만들어져 있다. 여기서 HDD 의 head arm 이 disk platter 위를 움직이면서 read/write 를 하게 된다. 이때 이 head arm 이 움직이는 길을 만들어주는 것이 servo sector 이다.
일단 HDD 를 구성하는 flatter 내부를 보자. 보다시피 servo mark 가 존재하고, servo mark 사이에 data 를 write 하게 된다.(좀 더 자세한 내용은 ref. 4를 참고하자)
ser

그러니 만약 degaussing 으로 servo sector 가 사라졌다면, platter 를 빼서, servowriter 로 다시 servo sector 를 그려줘야 한다.
우리는 자전거를 타면서 넘어지지 않기 위해서 페달을 돌리고, 핸들을 좌우로 꺾는다. 그리고 돌부리가 보이면 핸들을 꺾어서 피하고, 다시 원위치로 돌아오는 등 상황에 따라서 자전거를 제어한다.
이렇게 상황(output) 에서 오는 결과(feedback) 을 보고, 다음 동작(input) 을 하는 것을 이야기한다.
Degaussing 이후에 HDD 를 재사용할 수 있나?
요즘 디가우징(degaussing) 이 이슈이다. 그래서 관련해서 HDD 드라이브에 대해 좀 더 알아보기로 했다.
디가우징을 하면 데이터가 사라진다는 것은 알고 있다. 그럼 이 degaussing 을 한 HDD 를 다시 사용할 수 있을까??
degaussing tool 에 따라 다르다
결론은 degaussing tool 에 달려있다. degaussing 을 할 때 servo mark (또는 servo sector 라고 함) 를 지우느냐 그렇지 않느냐에 달려있다. ref. 3을 보면 servo mark 를 살리는 degaussing tool 도 존재하는 듯 하다.servo mark, servo sector
그럼 이 servo sector 가 무엇이길래 이것에 따라 HDD 를 다시 사용할 수 있기도 하고 없기도 할까?
HDD 는 아래와 같이 만들어져 있다. 여기서 HDD 의 head arm 이 disk platter 위를 움직이면서 read/write 를 하게 된다. 이때 이 head arm 이 움직이는 길을 만들어주는 것이 servo sector 이다.
 |
| 출처 : https://ayende.com/blog/174561/the-guts-n-glory-of-database-internals-managing-records |
일단 HDD 를 구성하는 flatter 내부를 보자. 보다시피 servo mark 가 존재하고, servo mark 사이에 data 를 write 하게 된다.(좀 더 자세한 내용은 ref. 4를 참고하자)
ser

servowriter
servowriter 는 HDD 를 만드는 공장에서 platter 를 묶어서 HDD 로 만들기 전에 platter(raw media)위에 servo track 들을 그려준다.그러니 만약 degaussing 으로 servo sector 가 사라졌다면, platter 를 빼서, servowriter 로 다시 servo sector 를 그려줘야 한다.
Servo(Servomechanism)
서보메카니즘은 "피드백 제어 시스템" 이다. ref. 1 의 설명에 나와 있지만, 자전거타기를 생각하면 이해하기 쉽다.우리는 자전거를 타면서 넘어지지 않기 위해서 페달을 돌리고, 핸들을 좌우로 꺾는다. 그리고 돌부리가 보이면 핸들을 꺾어서 피하고, 다시 원위치로 돌아오는 등 상황에 따라서 자전거를 제어한다.
이렇게 상황(output) 에서 오는 결과(feedback) 을 보고, 다음 동작(input) 을 하는 것을 이야기한다.
References
[컴][스크랩] 그래픽 관련 이야기
graphics / 그래픽 이론 / GTA 관련 그래픽
그래픽 관련 이야기
- http://www.adriancourreges.com/blog/2015/11/02/gta-v-graphics-study/
- Part 1: Dissecting a Frame
- Part 2: LOD and Reflections
- Part 3: Post-Effects
[컴][보안] 로그인 관련 보안 2
로그인과 보안 / secure login / 로그인 고민


server 가 client 로 부터 symmetric key 를 받고나서 server 는 해당 key 를 어떤 user 의 key 라고 알고 있어야 한다. 그래야 해당 user 의 request 가 오면 그 key 를 사용해서 복호화(decryption) 을 할 수 있다. 이를 위해서 DB 에 저장이 필요하다.
이 때 token 이 있는 경우라면, token 을 보고 user 를 구분할 수 있다. 하지만, token 이 없는 경우라면, 임시로 저장을 해 놓아야 하는데, 이를 위해서 phone number 를 public key 로 암호화 해서 보낸다.
하지만 여기서 "폰번호" 는 임시 token 으로 사용하는 것이라, 실제 id 와 연관된 db 에 저장하지 말자. 실제 id 로 사용되는 폰번호와 관련해서 사용하면 공격자가 이상한 값이나 존재하는 값과 비슷한 값을 보내는 경우 다른 사람이 사용하는 record 에 저장하는 문제가 생길 수 있다.
이상황에서 고려할 수 있는 hacking 은 누군가(여기서는 A라고 칭하자.) 의 핸드폰을 몰래 가져다가 public key 를 공격자의 public key 로 교체하고 A 에게 다시 돌려주는 것이다.
이 상황은 ssl 인증서로 무력화 될 수 있지만, 폰을 훔쳤을 때 인증서도 조작할 수 있다.
그러면 A 는 이 public key 를 가지고 통신을 하겠지만, 직접 server 와 통신할 수 없다. key 가 틀려서. 그래서 domain 을 공격자의 server 로 변경해 놓는다.
이글 이 도움을 준다.
목차
- 로그인 관련 보안 - 1
- 로그인 관련 보안 - 2


handshake - exchange the symmetric key
여기서 관건은 MitM 공격이 ssl 을 해놨을 때 틀린 CA 에 대해서 volley (정확히는 HttpsConnection) 가 verification 을 해서 error 을 내뿜으면, 굳이 이 작업을 하지 않아도 될 듯 하다. 그러나 이것은 실제 test 를 해보기 전에 아직 확신할 수 없다.client <-------------> serverrequest key ----> <---- public keysymmetric key ---->
public key 를 server 에서 받지 않는다.
ssl/https 에서는 public key 를server 에서 받은 후 그 public key 를 이용해서 symmetric key 를 주고 받게 된다. 이 경우에 인증서를 인증할 수 있기에 이렇게 한다. 하지만 나는 보내주는 public key 가 누가 보냈는지 알 수 가 없다. 중간에서 공격자가 보내도 그냥 맞는 거구나 하고 보내 버릴 것이다.server 가 client 로 부터 symmetric key 를 받고나서 server 는 해당 key 를 어떤 user 의 key 라고 알고 있어야 한다. 그래야 해당 user 의 request 가 오면 그 key 를 사용해서 복호화(decryption) 을 할 수 있다. 이를 위해서 DB 에 저장이 필요하다.
이 때 token 이 있는 경우라면, token 을 보고 user 를 구분할 수 있다. 하지만, token 이 없는 경우라면, 임시로 저장을 해 놓아야 하는데, 이를 위해서 phone number 를 public key 로 암호화 해서 보낸다.
하지만 여기서 "폰번호" 는 임시 token 으로 사용하는 것이라, 실제 id 와 연관된 db 에 저장하지 말자. 실제 id 로 사용되는 폰번호와 관련해서 사용하면 공격자가 이상한 값이나 존재하는 값과 비슷한 값을 보내는 경우 다른 사람이 사용하는 record 에 저장하는 문제가 생길 수 있다.
- token 을 가지고 있는 경우 : token 을 보고 판별한다.
- token 이 없는 경우 : 폰번호를 public key 로 key 를 주고받을 때 같이 보낸다.
- 가입이 이미 되어 있는 경우
- 가입이 안된 경우
Hacking
아래와 같은 공격이 가능하다. 하지만 아래와 같이 할 것이라면, 차라리 가짜 app 을 하나 만들어서 비밀번호를 입력하게 하는 것이 훨씬 간단하다. 그래서 그나마 공격자가 선택하는 방법은 public key 를 바꿔 놓는 수준이 될 듯 하다.공격자가 자신의 server 로 접속하게 해서 비밀번호를 알아낸다.
이상황에서 고려할 수 있는 hacking 은 누군가(여기서는 A라고 칭하자.) 의 핸드폰을 몰래 가져다가 public key 를 공격자의 public key 로 교체하고 A 에게 다시 돌려주는 것이다.
이 상황은 ssl 인증서로 무력화 될 수 있지만, 폰을 훔쳤을 때 인증서도 조작할 수 있다.
그러면 A 는 이 public key 를 가지고 통신을 하겠지만, 직접 server 와 통신할 수 없다. key 가 틀려서. 그래서 domain 을 공격자의 server 로 변경해 놓는다.
- public key 변경
- domain 변경(or DNS 조작)
- auth-token
- 비밀번호
대처
이 상황을 막고자, public key 를 쉽게 바꿀 수 없도록 한다. 그 방법으로 public key 를 file 자체로 놔두지 않고, xor 등의 연산을 통해 만들어 사용한다. 그리고, crc 등의 방법을 사용해서 변경되지 않음을 확인한다?이글 이 도움을 준다.
- public key 를 xor 등의 연산을 통해 획득
- CRC 등의 방법을 이용해서 public key 내용이 변하지 않음을 확인.(이부분도 공격자가 변경 해 놓을 수 있다. 하지만 이런 식으로 힘을 드리는 것보단 차라리 app 을 교체해 놓는 것이 낫다.)
- 이체 후 서버에서 고객의 email 등(또는 GMS 등, 실제 서버만이 가능한 것)으로 알림을 준다. (폰으로 주는 것은 안된다. 공격자가 이미 전화번호를 알고 있어서 sms 를 흉내내서 보낼 수 있다.)
이것은 고객이 자신의 송금 명령이 제대로 된 서버에게 보내졌는지를 확인하는데에 도움을 준다.
[컴][보안] 로그인 관련 보안 1
2015년10월에 정리한 글을 다시 옮겨왔다.
Toss 의 로그인
Toss 가 본인 명의의 휴대폰 1대에서만 사용가능하다고 한다.송금이 사용자의 휴대폰에서만 가능하다.
그래서 자신이 직접 전화번호(phone number) 를 입력할 수 없다.
폰번호, 기기 ID 확인은 어디서?
폰번호 + 기기 ID (IMEI) 가 일치해야 할 듯 하다. 이것을 통신사에서 확인할 수 있나? 아니면 server 에 가지고 있어야 하는가?
- 사용자의 비밀번호를 아는 경우 : 사용자의 폰이 아니라서 불가능
- 사용자의 폰에서 시도하는 경우 (훔친 경우) : 사용자의 비밀번호를 몰라서 불가능
- 사용자의 폰을 복제하는 경우 : 새롭게 login 을 하면 문자가 날라온다. 그러므로 걸릴 듯 하다.
- 사용자의 폰을 훔친경우 + 비밀번호를 아는 경우 : 어쩔 수 없다?
처음에 등록하는 암호가 이들이 사용하는 Login password 인 듯 하다.
이 값을 받아서 hash 해서 저장하고, local 에도 hash value 로 저장 해 놓는다.
그리고, 전화번호와 pw 를 보내서 인증을 받는다?
toss 가 local 에 가지고 있는 값, TOSS.xml
<?xml version='1.0' encoding='utf-8' standalone='yes' ?>
<map>
<string name="gaCode">9WOv+FvTQXaaU2+aNj1DTw==
</string>
<string name="seqNo">zeYYBd62OnqMld4PxW64h++T+yhxeq3wA+Cb3BTBJWM=
</string>
<string name="aesKey">xOolFn/09ZO1boBpzGsMw3sWQ3AnlstqHfqPc9k+PJUhksJN0aRU7J631l2oLcme
</string>
<string name="pKey">Dw0tPa4Nm58Dt7UxfEuk7tOs7VSQ9pZPOMQ+VGthUU1HKDwTxcjeULVdwdIzQZkh
</string>
<string name="timestamp">RNZp58Zh16VZs4IKulvXtQ==
</string>
<string name="promotion"></string>
<string name="privateKey">...
</string>
<string name="initData">...
</string>
<string name="pNumber">5bEKGSs6BbE2lE4vAt32lQ==
</string>
<string name="hasSetTossAlarm">9zV6TSbGJjPn0EnPdHkCxA==
</string>
<string name="birthDate">y/6msagccRolTPjekUgFCg==
</string>
<string name="name">4Ta03cJDFgrqcAT0RUgdJA==
</string>
<string name="faultCount">xfjOGX+ONgBoI7KVMAD40g==
</string>
<string name="INIT">9zV6TSbGJjPn0EnPdHkCxA==
</string>
</map>
SSL에서 Main-In-The-Middel Attack
Login 2
여기 글 처럼 auth token 을 쓰자. 그리고 비밀번호를 수정할 때 마다 auth token 이 다시 만들어지게 된다. 이러면 아래의 고민 중 credential 을 stolen 당할 때 client 에 암호화 과정이 들어가 있어서 hacker 들이 추측할 수 있는 여지가 줄어든다.
조금 다른 점은 새롭게 로그인할 때마다 시간을 기록하고, auth token 을 다시 만든다? time 을 더해서?
그러면 한 앱에서 한개만 가능할 것이다.
이건 처음에 생각한 것과 비슷한데, 처음 생각은 auth token 처럼 고정적인 token 을 만들생각을 안하고, expired token 만 고려했는데, 이번엔 2개의 token 을 사용하자.
이 Auth Token 을 가지고 있고, 이녀석을 가지고 다시 expired 가 있는 token 을 얻어오도록 하자.
https sniff, MITM
MITM 의 공격에서는 보통 인증서가 잘못 되었다고 뜬다. (참고) 이것이 volley 에서 어떻게 동작하는지 확인이 필요하다. 만약 error 가 된다면, 굳이 https 가 공격 당할 걱정을 안해도 될까?? 일단 가능할 듯 하다.MITM 공격에 대비해서 https 위에 다시 한번 https 를 얹어놓자. 정확히 비슷하지는 않지만, sniffing 을 대비해서 한 번 더 encryption 을 해 놓는다. 이부분은 https 와 비슷하게, asymmetric encryption 으로 symmetric 의 key 를 주고 받고, 이 key 를 이용해서 encrypt 해서 보내면, server 에서 decrypt 를 한다.
symmetric encryption 의 key 는 주기적으로 server 에서 교체하면 된다.
client 의 public key 는 client 에 대한 인증역할도 같이 할 수 있다. 그러기 위해서 각 user 의 private key 를 저장하고 있는다.
auth token, expired token
expired token 이 csrf 공격의 방어 기능을 할 수 있다. 그렇다면 expired token 의 generation 을 절대적으로 핸드폰에서만 가능하도록 해야만 한다. phone number 를 가져와서 expired token 의 hash 를 만들때 사용한다.auth token , no expired token
auth token 만을 이용하자. 이러면, rooting 된 폰에 의해서 auth token 을 stolen 되고, data/data 내용을 그대로 가져가서 새로운 폰에서 toss 를 시작한다고 하면, 여기서 다 잘 된다고해도, 송금할 때 결국 비밀번호를 다시 입력해야 한다. 그래서 괜찮다.폰정보를 가지고 있을 필요는 없어 보인다. 이 또한 복제될 수 있어서.
expired token 이 필요치 않은 이유
expired token 은 sniffing 때문에 필요하다고 생각했는데, expired token 대신에 auth token 을 사용하다가 sniffing 을 당한다고 해도, 결국 비밀번호를 다시 입력 하는 부분 때문에 사용할 수 없을 듯 하다.sniffing 에 대한 대비
위의 <https sniff, MITM> 를 참고하자.expired token 등 sniffing 될 요소들을 사용할 때 한번 더 암호화 하고, ssl 을 사용한다. 이것은 hacked 된 https line 에서 해킹이 어렵게 해준다.
그러면 비밀번호를 보내는 순간에 sniffing 을 당하지 않아야 하는데.... https 같은 경우 secured line 이 아닌 상황이라면, 비밀번호가 노출되는데, 이때를 위해 public key 로 암호화를 걸어놓자.? 하지만 이경우도 brute force 로 알아낼 것이다. 왜냐하면 toss 의 경우는 "숫자4+문자" 의 형태라, 경우의 수가 작은 편이다. public key 가 노출된 상황이라면, 모든 case 에 대한 table 을 가지고 있게 되고, 이런 상태라면 암호화를 한 비밀번호도 손쉽게 노출된다.
그러면 주기적으로 public key 를 갱신해준다. ? 그러면 public key 를 저장하지 말고, network 로 받는다. 하지만 이 경우에 xor 등으로 난독화 하려는 계획이 어려워 질 수 있다. 물론 2개를 받아서 xor 후에 사용할 수도 있을 듯 하다.
송금 수신자 정보 암호화
만약 phone 을 hacking 하지 않고, sniffing 만 하는 경우에, token 을 알고 있다면, 송금이 가능해 진다. 이때 비밀번호가 같이 가기에 괜찮은데, 이렇게 되기 위해서는비밀번호와 수신자 정보를 같이 암호화 해야 한다. 따로 암호화 하면, 비밀번호 부분을 가져다 이용할 수 있다.
그래서 encrypt("비밀번호","수신자정보") 형식등으로 암호화를 해서 보내야 한다. 그러면 비밀번호를 모르기에 암호화 키를 알아도 적절한 값을 만들 수 없다.
그런데, 비밀번호가 간단하니, 여기에 "hashed 폰번호" 또는 "hashed timestamp" 를 추가로 이용한다.?
rooting 에 대한 대비
그리고 auth-token 은 rooting 등으로 쉽게 가져갈 수 있다. 이것은 다른 app 들에서 하듯이 rooting 인 phone 에서 실행이 안되도록 하는 방법이 있다. 하지만 이것도 우회하는 법들이 생겨났기에, 임시방편밖에 안된다.rooting 을 하고, token 을 가져간 공격자는 이것을 가지고, 시도를 할 수 있지만, 다행히 비밀번호를 몰라서 바로 hacking 당하지 않는다. 그러므로 잘못 시도된 비밀번호에 대해 user 에게 알려줄 필요가 있다.
처음 등록시 password 전달
처음에 public/private key pair 를 가지고 있는 상태가 된다. public key 를 client 가 가지고 있는다. 이 key 는 처음 password 를 등록할 때 쓰이게 된다.client 에서는 public key 로 암호화 한다. 이 때 random 값을 같이 준다.
- public_key_encrypt(pw, random)
key 교체시
key version 관리가 필요하다. 서버에서 key 를 바꾸고 새롭게 key 를 장착할 때 기존의 모든 client 가 새로 등록을 할 수 없게 된다. 이 경우에 새로운 버전을 설치하라고 알려줄 필요도 있을 듯 하다.default public/private key pair
- 처음에 접속하면 받도록 하자. 어차피 공개된 녀석이라 굳이 가지고 있을 필요는 없을 듯 하다.
- 이녀석은 client 에서 server 로 보내기만 하는 경우이면서
- 크기가 작은 녀석을 암호화 할 때 사용가능 하다.(asym 은 암호화 속도가 느려서 큰 것은 힘들다.)
symmetric 암호 key
- public_key_decrypt<유저 입력 password + 랜덤 값+ 폰 넘버>
임시 key 등은. 하지만 여기서는 public key 를 가지고 있는 쪽이 client 여서 client 가 결정을 내린다. public key 로 암호화 해서 보내면, private key 를 가진 server 만 알 것이다.
client 에서 보낸 암호를 가지고 symmetric 암호화를 하면 된다. 이 때 symmetric 암호키는 랜덤한 값이며, 항상 password 를 보내는 순간에 password 와 같이 보낸다. 그리고 symmetric key 를 받자마자 서버가 symmetric 암호화로 data 를 보낸다. 이러면, sniffing 을 당해도 rainbow attack 등을 피할 수 있다. 그리고 매번 변경돼서, token 을 가져가도 크게 의미가 없다. 누군가 token 을 가지고 key 를 시도한다해도, 암호를 같이 encrypt 하지 않았다면 인정받지 못하게 된다.
세션이 없기에, db 에 임시 저장이 필요하다? 이렇게 되면, 암호가 invalidate 되는 시점도 정확히 정해져야 한다. random 한 값이 사용되므로, 항상 db 에 저장해야 할 필요가 있다.TokenAuthentication 도 token 을 가지고, 이녀석에 해당하는 user 를 가져오는데, 이것처럼 TokenAuthentication 일 때 symmetric key 도 같이 가져오도록 한다.
이 상황은 하지만,처음 로그인에서는 가능하지만, 이후에 token 으로 login 을 하는 경우에는 적합하지 않다. 송금을 누르고 송금정보가 날라갈 때 암호화할 key 가 이미 있어야 한다. 그렇지 않다면, 2번 왔다갔다 해야 한다.
만약 client 가 random 하게 값을 정해서 server 로 보냈다고 하자. 그렇다면, 누구나 그렇게 random 하게 만들어서 server 로 보낼 수 있다. 공개키는 얻을 수 있으니. 그러면 server 는 아무하고 encrypted 통신을 하게 된다. client 가 공격자인 경우도 생긴다.
Login

- 전화번호 : 노출
- public key : 해킹에 의해 노출
- 비밀번호 : 입력
- 비밀번호를 key logger 를 사용하지 않는한 안전하다고 가정.
여기서 문제는 rainbow table 로 경우의 수를 만들어서 던져볼 수 있다. 그래서 local 에서 credential 을 만들 때 hashing 을 한 번 하고, 그 값을 가지고 credential 을 만들어야 한다. 그러나 그래도 source 를 decompile 한다면, hashing 횟수나 salt 를 쉽게 파악할 수 있을 듯.
time delta
time delta 를 쓰지 않으면, 결국 client 를 hacking 해서 보안이 문제될 수 있다.
그래서 본인 휴대폰 인증받는 순간(문자, ARS 등) 의 시간을 기준으로 한 time 를 만들어서 보내자.
그러고 인증이 통과되면,(로그인 완료후) 이 시간을 server db 에 저장 해 놓고,
time(sec.) 이 이 시간에서 멀지 않은 시간(약 30분?) 으로 setting 된다면,
ok 로 받아드린다.
정지방법
이 경우에 외부에서 정지시킬 수 있어야 한다.
공격
첫 인증시만 사용가능 하도록 : 이것은 ARS 인증? 등을 할 때, 인증이 성공한 경우에만(로그인을 하듯이) time 을 저장한다. 그 외의 경우에는 setCurTime 을 요청하지 않는다.
본인인증 확인 가운데에 설정을 하는 것이라, 노출되지 않는다?
credential 을 만들 때 전해준다.? : 이건 다른 쪽에서 비슷하게 흉내낼 수 있다. rainbow attack 이 들어올 것이다.
공격 상황
그래서 본인 휴대폰 인증받는 순간(문자, ARS 등) 의 시간을 기준으로 한 time 를 만들어서 보내자.
그러고 인증이 통과되면,(로그인 완료후) 이 시간을 server db 에 저장 해 놓고,
time(sec.) 이 이 시간에서 멀지 않은 시간(약 30분?) 으로 setting 된다면,
ok 로 받아드린다.
- 공격 유형 : 이것은 해커가 public key, id, pw 를 모두 알고 있는 상태에서 해 볼 가능성이 있는 공격이다. 근데 pw 가 노출될 확률이 낮다.
폰을 도난 당한 경우
누군가 폰을 훔쳐갔을 경우, 도둑이 rooting 을 할 수 있다. 그러면, SharedPreference 등에 접근할 수도 있고, 그대로 app 을 사용할 수 있다.정지방법
이 경우에 외부에서 정지시킬 수 있어야 한다.
- 다른 폰에서 앱을 새롭게 login 을 하거나, : time-delta 로 이전 로그인을 차단한다. / 비밀번호를 변경한다.?
- web 을 통해 정지 명령 : server db 에서 time 을 조작해서 time-delta 를 이용할 수 있다.
공격
- 해킹을 통해, credential 을 얻은 경우 : 이 경우 시도해도, 위의 "정지방법" 에 의해 time-delta 가 맞지 않아서 걸린다. 그래서 setCurTime 을 이용한 time 대한 수정을 하려고 할 것이다.(아래 참고)
- public key, id, pw, 얻은 경우 : time delta 를 알아내기 위해, 다양한 time 을 넣고, credential 을 만들고 사용하려 할 것이다. 이런 접근이 있는 경우 서버에서 감지해서 처리해야 한다. -> 패스워드 변경유도
setCurTime 에 대한 공격
만약 이 request 를 외부에서 해 온다면? 이걸 어떻게 app 에서만 하도록 할 수 있나?첫 인증시만 사용가능 하도록 : 이것은 ARS 인증? 등을 할 때, 인증이 성공한 경우에만(로그인을 하듯이) time 을 저장한다. 그 외의 경우에는 setCurTime 을 요청하지 않는다.
본인인증 확인 가운데에 설정을 하는 것이라, 노출되지 않는다?
credential 을 만들 때 전해준다.? : 이건 다른 쪽에서 비슷하게 흉내낼 수 있다. rainbow attack 이 들어올 것이다.
공격 상황
- 해커가 credential 을 가지고 있다.(public key (비밀번호 + id + timedelta )) 그래서 이 credential 에 time-delta 가 들어가는 것을 알고, 이 time-delta 를 맞추기 위해 setCurTime 을 특정 시간으로 조정하려 할 때(무자비하게 여러번 시도 할 것이다.),
- credential 을 새롭게 만드는 것도 시도할 수 있지만, 비밀번호를 모를 확률이 크다.
본인인증
- 한국 모바일 인증 > 개인정보취급방침 : 여기에 보면, toss 가 처음에 인증을 위해 필요한 항목을 입력하는 것과 일치하는 것을 알 수 있다. 아래 2가지 항목을 확인하자.
- 본인확인기관(이동통신사, 공인인증기관 등)을 통한 본인확인 정보의 일치여부 확인 : 휴대폰번호, 통신사, 성명, 성별, 생년월일, 내/외국인 구분
- 휴대폰 사용자 확인을 위한 SMS인증번호 전송
위의 인증을 위해서라도, server 에서는 "전화번호"를 가지고 있어야 한다.
OAuth 등의 로그인을 고려해 보자. facebook 같은 녀석으로 한번 login 을 하고 나면, 그 이후로 access token 으로 이녀석을 접근한다. 이것도 어쩔 수 없이 한번의 노출을 만들지만, 그 이후에 id/pw 는 노출되지 않으므로, 항상 id/pw 가 노출되는 것보다 현저하게 노출위험을 줄일 수 있다.
같은 의미로, app 이 처음 실행할 때만 id/pw 를 입력받도록 한다. 그리고 나서 access token 을 발급하자. 그러면, 이 access token 을 저장하고 있다가, 다시 app 을 실행하게 되면, 이 access token 을 보내고,
JWT vs Django login
Using JSON Web Tokens as API Keys 를 참고해서 login 을 위해 JWT 를 사용하기로 했다.
Redirecting Our Django Website to Our Ember App - Shippo
장점
- 위의 글을 참고한다면, 다양한 방법으로 token 을 이용할 수 있을 듯 하다.
- Django Rest Framewrok jwt 를 이용하면, permission_class 등의 방법을 그대로 사용할 수 있다.
Django login 도 같은 기능을 제공하긴 한다. csrftoken 을 이용해서, 그런데 문제는 site 에 접근하지 않고, csrftoken 을 받아오는 방법을 찾기가 시간이 걸린다. 그리고 확장성도 떨어진다. Django 자체의 login 과 연동하긴 좋을 수 있다.
client 가입 알고리즘
서버
IMEI 와 전화번호를 서버에 저장한다.
처음 인증할 때 "통신업체"를 통해 폰이 본인인 것을 확인한다.(아무래도 handset 자체에 대한 검증은 하지 않는 듯 하다.)- public key 를 client에 넘겨준다.
- 이때의 datetime 을 기록한다.
client
- public key 를 저장한다. 저장시 여기를 참고
- IMEI 와 timestamp 를 public key 를 이용해서 암호화해서 저장하고, 이것을 사용한다.
- 이것이 결국 password 역할을 할 것이다.
- 해커는 이 날짜의 존재를 모르기에 만들기 어려울 것이다.
- 만약 decompile 로 날짜와 함께 만들어진다는 것을 안다고 해도, 이 날짜가 특정시간에 맞춰야 하기에 그 특정시간을 알 수 없다.
- public key 를 가지고 있어도 되고, 버려도 된다.
- 이 암호화된 IMEI 와 phone number 를 server 로 날려서 token 을 받는다.
서버
- 서버에서는 client 에서 온 암호화된 text 를 private key 로 decrypt 한다.
- 그리고 날짜를 public key를 넘겨준 날과 비교한다. 시간상 10분(?) 이내라면 허락한다.
- 그 이외의 날짜가 같이 IMEI 와 encrypt 된 경우에는 허락하지 않는다.
asynch algo 를 사용한다. timestamp 를 넣어서 암호화된 text 가 steal 되어도 안전하게 만든다.
client 에서 자동 로그인
- phone number SIM 에서 읽기
- device id 가져오기
- phone_number + device id 를 가지고 encryption or hashing
- 이 값을 server 로 전송해서 login
pw 암호화
device id 를 phone number 를 key 로 해서 암호화 한다. 이 때 key 는 phone number 를 4자리 단위로 shift 해서 만든다.- 01023026616 ---> 66160102302
JWT
djangorestframework-jwt 사용- 접속시에 token 을 만든다.
- 이 token 은 expiration time 을 갖는데, 이 expiration time 이 끝나기 전에 refresh 를 하면 계속 유지된다. (JWT_EXPIRATION_DELTA)
- 하지만 이런식으로 같은 token 이 유지되는 시간도 한계를 정할 수 있다.(JWT_REFRESH_EXPIRATION_DELTA)
- 어느정도 시간 유지가 적절한가?
- 계속 화면을 띄워놓고 있는 경우에 계속 refresh 를 하기는 부담스럽다. 차라리 refresh 를 못하게 하고, expiration time 을 1일 정도로 가져가는 것이 나은가?
IMEI 를 확인하지 않는경우
SIM의 MSISDN + IMSI 를 복제된 경우
여기서 toss 처럼 인증을 하면, 문자를 받거나, 전화인증에서 양쪽에 전화가 걸려올 수 있다. 그래서 노출될 수 있다. 하지만 그 순간에 본인이 핸드폰을 못봐서 넘어갔을 확률이 있으므로, 이를 대비해서 로그인 후 "로그인했다" 는 정보를 시간과 함께 sms 로 전달해 준다.그러므로 굳이 IMEI 정보를 알고 있지 않아도 될 듯 하다.
로그인
1번째 로그인
폰에서 app 을 깔고, 처음 로그인 할 때 (전화번호, 이름, 기기 id ) 를 server에 저장그리고 계속 이 번호로 로그인한다.
처음에 비밀번호를 등록할 때,
이 때 특정 public key 를 보내준다. ???
그럼 public key 로 특정 값을 암호화 해서 server 로 보내게 되면 server 는 그 값에 해당하는 private key 를 가지고 그녀석이 맞다는 것을 확인한다. 그런데 이것은 결국 https 라서, 전체적으로 이런 일을 중복해서 할 이유는 없다.
2번째 로그인
2번째 부터는 phone number 와 기기의 id 를 가지고 로그인한다?여기서 jwt 를 얻어온다. 그리고 이 값으로 통신한다.
phone number 의 저장
phone number 는 서버의 db 에 저장된다. 서버에서 직접적으로 sms 를 보내는 등의 일을 해야 하기 때문에 어쩔 수 없이 노출된 값을 가지게 된다.다만 DB에 암호화된 값으로 저장하고, decode 해서 사용할 수는 있다. 이 경우는 key 를 어떻게 가지고 있어야 할 지 고민해야 한다. 장고의 SECRET_KEY 를 이용할 수도 있다.
패스워드, hash(phone_number + Device ID)
송금할 때 사용하는 패스워드 이외에는 패스워드가 따로 없다. 대신에 기기의 ID(Device ID) 를 이용한다. 이 녀석을 직접적으로 pw 로 사용해서 확인할 필요는 없고, 이 ID 를 seed (또는 salt) 로 이용해서 나온 값(hash 값이면 될 듯 하다.)을 이용한다.이 값을 server 의 DB 에 저장하고, 매 로그인할 때 client 에서 (phone-number, device id) 로 hash 값(또는 암호화한 값)을 만들어 보낸다.?
client 에 암호화, 해시함수를 두는 경우
이것이 server db 를 해킹한 사람들이 client 의 library 에 대한 decompile 을 시도할 것이다.그러면 시간이 걸리겠지만 가능해 진다. (사실 암호화나, hash 함수나, 이름만 알면 그냥 사용하면 되고, 단순히 seed 나 salt 값을 어떻게 적용했는지의 문제일 뿐일 수 있다.) 그러면 hacking 해서 번호와 device id 에 대한 해독이 가능할 수 있다.
하지만 이 경우에도 phone number 의 암호화가 되어 있는 경우에는 알아내기 힘들 수 있다.
이 부분이 binary 로 되어 있어 decompile 이 어렵고 시간이 걸려서 포기하는 집단도 있을 것이다.
application server 에 암호화, 해시함수를 두는 경우
기기 id 와 폰 번호를 바로 server 로 넘기고, server 는 이 값을 가지고 hash function 을 이용해서 비밀번호를 만들어 저장해 놓는다.이 경우 hash function 은 노출되지 않아서 server db 를 해킹한 해커는 application server 에 대한 해킹을 다시 하지 않는 이상 db 에서 의미있는 값을 얻기 어렵다.
하지만 client 쪽에서 format 만 맞춰서 쉽게 request 를 날릴 수 있게 된다. request 날리면 서버에서 알아서 암호화를 하고 비교를 할 테니, 암호화의 의미가 server db 가 해킹당했을 때의 대비만을 위한 것이 된다.
만약 phone-number 가 노출된 경우
phone number 를 phone SIM 에서 바로 가져오기 때문에(SIM 에서 안드로이드 SDK 를 통해) 직접 입력하지 않는다. 그래서 phone 의 SIM 에 새겨진 번호를 조작하지 않았다면 괜찮다.만약 SIM 을 조작했다면?(복제폰?)
전화번호가 같더라도, device id 가 같지 않다. 그래서 이 경우에는 device id 까지 해커가 훔쳐야 한다.만약 SIM 을 복제 하고, device id 도 복제했다면
폰으로 시도
비밀번호를 몰라서 막히던지, 비밀번호 재설정을 할 때 막힌다.비밀번호 확인작업을 하는데, 이때 비밀번호 재설정도 할 수 있다. 그런데 재설정 작업은 이들이 자신만의 방법(계좌에 돈 보내고, 그 날짜로 확인)을 이용한다. 이과정 때문에 어쩔 수 없이 공인인증서 등으로 확인이 된다.
그렇기 때문에 여기서 막힌다.
pc로 시도
여기에 어떻게 해서 이들이 send request format 에 맞춰서 송금 명령을 server 로 보냈다고 하자. 그러면 여기서 jwt token 을 얻고, 이 token 으로 계속 통신을 할 것이다. 하지만 송금할 때에는 다시 비밀번호를 직접 입력해야 한다. 결국 비밀번호를 몰라서 실패한다.기기 ID 가 노출되어서 알려진 경우
기기id가 노출돼서 그것을 카피한 핸드폰으로 시도 해도 암호방식을 해킹해야 한다.암호방식 binary
암호방식은 이것이 일단 binary라서 바로 해독은 불가능하지만 해킹이 불가능은 아니다. 그래도 memory 채 가져와서 사용할 수 있을지도.?그런데 시드 서버가 갖고 있어야 하는가?
암호화한 값을 비교 할 수만 있면 된다.
암호를 해독할 필요가 있나?
서버가 털릴때를 대비해야한다.
암호화도 털려서 온다해도 서버에서 인증이 거부 될만한 요소를 가지고 있는가?
서버가 해킹될 때
서버가 털리면- 암호화된 패스워드(기기id, IMEI)
- 전화번호 : 암호화 하는 것이 나을 듯 하다. 속도의 저하가 있을 수 있지만 보안이 더 중요하다.
- 실명
- 암호화된 송금 비밀번호(hashed value)
송금 비밀번호
송금 비밀번호는 계속해서 다른 기기에서도 일치여부를 확인할 수 있어야 한다.그래서 서버쪽에서만 암호화 또는 hashing을 한다.
hashing 의 salt 를 무엇으로 해야 하나?
기기가 바뀌어도 유지돼야 해서, device id 는 안된다.폰번호가 바뀐 경우는 모르겠다.
명확한 것은 실명인 듯 하다.
스니핑에 대한 고려로
송금 비밀번호를 서버쪽에 보낼 때 암호화가 필요한가? 필요할 듯 하다. 스니핑을 하지 않더라도, 임의로 값을 만들어서 보내는 경우에 앱을 통해서가 아니라 외부툴일 가능성이 있는데 외부 툴로 가능하게 되면, 쉽게 뚤린다. 토스의 5자리의 경우는 특히.그러므로 보내기 전에 한번 가공을 하고, 그 값을 서버 DB 에 저장된 값과 비교하는 것이 나을 듯 하다.
이것도 마찬가지로 server db 가 해킹당한 후에 해커가 client 의 decompile 을 노릴 수 있다.
서버쪽에서 해킹 당한 경우
이 경우 hashing 되어 있어서, hashing algorithm 을 적용하고, salt 를 파악하지 못하면 의미가 없다. application server 도 해킹을 같이 당해야 한다.client 에서 당하는 경우
- 클라이언트에서 입력한 상황에서 메모리의 값을 steal 할 확률 : 이정도의 해킹이 쉽게 될지 모르겠다. 메모리 주소를 쉽게 알 수 없을테니. 일단 잘모르겠다.
- 키에 대한 로깅으로 해킹하는 방법이 있을 수 있는데 : 키에 대한 로깅을 방지하려고 난독 키보드를 이용한다.
[컴][책] Reverse Engineering for Beginners
실전연습으로 완성하는 리버싱 책 / 리버싱 책 / 리버스 / reversing / reverse engineering / 리버스 엔지니어링 / 자료 / 책 /
"실전연습으로 완성하는 리버싱"의 원본
- beginners.re/ : 무료로 pdf 를 받아볼 수 있다.
[컴] UFS vs eMMC
내장 메모리 스펙 / 플래시 메모리 스펙 / spec / specification
일단 UFC 나 MMC 나 전부 스마트폰등 모바일 기기에 들어가는(내장) 메모리에 사용하는 표준이다.
그래서 대체로 스마트폰에 쓰이지만 어디서나 이 표준을 구현해서 사용할 수는 있다.
여하튼 아래 도표를 보면 알 수 있듯이 이 표준을 속도별로 구분하면 eMMC 다음 버전이 UFC 가 되는 것이다. 물론 이것은 eMMC 표준이 더이상 발전을 안한다는 가정이 있다.
삼성전자는 2015년 2월 128GB UFS(Universal Flash Storage) 내장 메모리를 양산
UFS vs eMMC
UFS(Universal Flash Storage) vs eMMC(embedded Multi-Media Card)일단 UFC 나 MMC 나 전부 스마트폰등 모바일 기기에 들어가는(내장) 메모리에 사용하는 표준이다.
그래서 대체로 스마트폰에 쓰이지만 어디서나 이 표준을 구현해서 사용할 수는 있다.
여하튼 아래 도표를 보면 알 수 있듯이 이 표준을 속도별로 구분하면 eMMC 다음 버전이 UFC 가 되는 것이다. 물론 이것은 eMMC 표준이 더이상 발전을 안한다는 가정이 있다.
- eMMC --> UFS
 |
| 출처 : ref. 1 |
eMMC
eMMC는 패키지이다. '컨트롤러'와 '낸드플래시 메모리' 를 함께 가지고 있다.- 컨트롤러
- 낸드플래시 메모리
삼성전자는 2015년 2월 128GB UFS(Universal Flash Storage) 내장 메모리를 양산
UFS 2.0 interface
- 국제 반도체 표준화 기구 ‘제덱(JEDEC)’의 최신 내장 메모리 규격
- 커맨드 큐 : SSD에서 사용 중인 속도 가속 기능 ‘커맨드 큐(Command Queue)’가 적용
커맨드 큐는 여러 개의 명령어를 동시에 처리할 수 있고 그에 따라 작업 순서도 변경할 수 있다.
eMMC 5.1 에도 command queue 가 적용됐다. - LVDS(Low-Voltage Differential Signaling) 직렬 인터페이스 : 이로 인해 full duplex 양방향 통신이 가능하다.
half duplex 는 무전기 같은 방식(한명이 이야기할 때 한명은 들어야 하고), full duplex 는 전화기 같은 방식으로 보면된다.(동시에 이야기하는)
See Also
References
- 모바일 기기용 낸드플래시 메모리의 진화, eMMC부터 UFS까지 , 삼성 뉴스룸
[컴][웹] 개인정보보호 자율점검 가이드라인
웹 보안 / 사이트 보안 / 정보보안 / 시큐러티 / security / 해킹방지 / 해커
개인정보보호 자율점검 가이드라인
그저 참고 자료로 올려놓는다.- 붙임1-개인정보처리_자율점검표.pdf
- 붙임2-개인정보보호_자율점검_가이드라인.pdf
- 출처 : 개인정보보호 자율점검 가이드라인 및 점검표, 2015-07-16, https://www.privacy.go.kr
개인정보 파기
② 정보통신서비스 제공자등은 정보통신서비스를 1년의 기간 동안 이용하지 아니하는 이용자의 개인정보를 보호하기 위하여 대통령령으로 정하는 바에 따라 개인정보의 파기 등 필요한 조치를 취하여야 한다. 다만, 그 기간에 대하여 다른 법령 또는 이용자의 요청에 따라 달리 정한 경우에는 그에 따른다.
[컴] Spectre
Microarchitectural Side-Channel Attacks
이 구성요소들은 미래의 프로그램의 행동 예측을 통해 프로세서의 성능을 향상시킨다.행동예측을 위해서 그 구성요소들은 과거 프로그램 동작과 관련된 state 를 유지한다. 그리고 미래 행동이 과거의 행동이랑 연관이 있거나 비슷할 것이라고 가정한다.
여러개의 프로그램들이 같은 하드웨어에서 동작할 때 (동시에 또는 time sharing 을 통해 ) 어느 한 프로그램에 의해 이뤄진 microarchitectural state 의 변화는 다른 프로그램에 영향을 준다. 결과적으로 이것이 한 프로그램에서 다른 프로그램으로의 의도치 않은 정보의 유출을 일으킬 수 있다.
과거의 작업들은 BTB, branch history, caches 을 통한 정보유출을 보여줬다. 여기서 우리는 Flush+Reload 와 그것의 변형인 Evict+Reload 를 사용해서 민감한 정보를 유출할 것이다.
이 기술들을 이용해서 공격자는 cache 에서 희생자(victim)가 공유한 cache line 을 추출할 수 있다.
희생자가 잠시 프로그램을 수행한 후에 공격자는 추출된 cache line(evicted cache line) 에 해당하는 주소에서 메모리를 읽는데 얼마나 시간이 걸리는지 측정하게 된다.
만약 victim 이, 모니터되고 있는 cache line 에 접근하면, 그 데이터는 cache 에 있게 되고, 접근은 빨라진다. 그렇지 않고, 만약 victim 이 그 line 에 접근하지 않았다면, read는 느리게 된다. 그렇기 때문에 access time 을 측정하는 것으로, 공격자는 victim 이 추출(eviction step)과 조사(probing step) 과정사이에서 monitored cache line 에 접근했는지 여부를 알 수 있다.
2개의 기술사이의 중요한 차이점은 cache 에서 monitored cache line 을 추출(evicting ) 할 때 사용되는 방법(mechanism) 이다.
Flush+Reload 기술에서는 공격자는 line 을 추출하기 위해 x86의 clflush 같은 기계어처럼 원래 그런 목적으로 만들어진 instruction을 사용한다.(dedicated machine instruction)
Evict+Reload 에서는 추출(eviction) 이 cache line 을 저장하고 있는 cache set 에서의 경합(contetion)을 만들어서 추출하게 된다. 즉, 다른 memory location 들을 접근해서 이 정보가 cache 로 들어오고 이전에 추출한 line 을 버리도록 만든다.
작성중...
See Also
References
[컴] Meltdown
요즘 CPU의 심각한 보안 구멍(security hole) 이 있다고 여기저기서 난리다. 그래서 내용을 좀 파보기로 했다.
일단 이 문제에 대해 자세한 설명을 해주는 page 는 아래와 같다.
크게 2개의 bug 가 보고 되었는데, meltdown 과 spectre 라 불린다.
- Meltdown
- Spectre
Meltdown
Out-of-order execution
Out-of-order execution 은 최적화 기술의 하나이다. 이 기술은 CPU core 의 모든 실행 단위(execution units) 에 대한 사용을 최대화 하기 위한 기술이다.(즉, execution unit 이 놀지않고 쉬지않고 일하도록 한단 이야기다.)CPU 가 instruction들을 "순차적인 프로그램 순서(sequential program order)"로만 처리하는 것 대신에, 모든 필요한 resource(자원)가 갖춰지자마자 실행하게 된다. 순서를 벗어나서 실행을 하기 때문에 이름이 out-of-order execution 이다.
이러면 현재 동작에 의해 execution unit이 점유되어 있는 동안에도, 다른 execution unit 들은 다른 것들을 실행할 수 있다. 그래서 instruction들은 그들의 결과가 architectural definition을 따르는 만큼 병렬로 실행될 수 있다.
좀 더 쉽게 이야기하면, 원래 프로그램은 프로그램 내에서도 분리될 수 있는 부분이 있다. 예를 들면, 아래와 같은 코드가 있다면,
(1) c = a+b (2) f = d+e (3) h = c+f(1) 과 (2) 는 아무런 연관성이 없기 때문에 병렬로 진행해도 된다. 만약 이것을 sequential program order 로 수행한다면, (1) 이후에 (2)가 진행되고, 그 후에 (3)이 진행될 것이다.
실제로, out-of-order execution을 지원하는 CPU 들은 추측해서 operation 을 수행하는 기능을 제공한다. 이 기능은 CPU가 instruction 이 필요해지고 commit되는 것인지 아닌지 대해 확실해 지기 전(즉, 결과를 확정짓기전에), 프로세서의 out-of-order logic 이 instruction들을 처리할 때까지는 수행된다.
In practice, CPUs supporting out-of-order execution support running operations
speculatively to the extent that the processor’s out-of-order logic processes instruc-
tions before the CPU is certain whether the instruction will be needed and committed.
모든 이전의 instruction 들의 결과를 commit 하기전에 프로세서가 operation 을 수행하는 것을 여기서는 out-of-order execution 이라고 하자.
branch prediction units
branch prediction unit 들은 어떤 instruction 이 다음에 수행될 지에 대한 학습된 추측(educated guess) 을 얻게 된다. Branch predictor 들은 조건이 실제로 정해지기전에 어떤 branch 의 방향으로 갈 것인지를 정하기 위해 노력한다.그래서 정해진 branch 에 있는 dependency 가 없는 instruction 들은 미리 수행되고, 만약 예측이 맞는다면 그대로 그 결과를 사용하게 된다.
만약 예측이 틀리면, reorder buffer 를 clearing 하고 unified reservation station 을 다시 초기화를 한다.
branch prediction 종류
- static branch prediction
- Dynamic branch prediction
- One-level branch prediction
- neural branch prediction
주소 공간 Address Spaces
translation table
각 프로세스들을 독립적으로 하기위해서 CPU들은 가상메모리 공간(virtual address spaces)을 제공한다. virtual address 들은 물리적인 memory 주소로 번역(translate)된다.virtual address spaces 들은 page 들의 집합(set)들로 나눠진다. "multi-level page translation table"을 통해서 이 page set들은 은 물리적인 메모리에 mapping 된다.
이 translation table 들은 가상주소에서 물리적주소로의 mapping 을 정의한다. 또한 readable, writeable, executable, user-accessible 같은 권한 체크(privilege check)를 수행할 때 사용되는 protection property 들을 정의한다.
- virtual address --> physical address
- protection property
이 덕에 각 process는 그들의 virtual address space 에 속해있는 data 에만 접근할 수 있다. 이것은 해당하는 translation table들의 user-accessible property 를 disable 하는 방법을 통해서 OS 에 의해 수행된다.
kernel address space
kernel address space 는 kernel 의 사용만을 위한 memory mapped 만을 가지고 있는 것이 아니라 user page 들에 대한 operation 들을 수행한다. 즉, data 를 그곳에 write 할 수 있다. 결과적으로, 모든 물리적 memory 는 일반적으로 kernel 에 mapped 된다.리눅스와 OS X 에서 이것은 direct-physical map을 통해서 이뤄진다. 즉, 모든 물리적인 메모리는 직접적으로 이미 정의된 virtual address 에 mapped 된다.
윈도우에서는 direct-physical map 대신에 paged pools, non-paged pools, system cache 라고 불리는 것들을 이용한다. 이 pool 들은 kernel memory space 에 있는 virtual memory 영역들이다. 이 virtual memory 영역들은 물리적인 페이지들을 virtual address 들에 mapping 해준다. virtual address 들은 memory 에 남거나 (non-paged pool) 또는 copy 가 이미 disk 에 저장됐기 때문에 memory 에서 지워질 수 있다.(paged pool) system cache 는 모든 file-backed page들의 mapping들을 포함한다. 이 memory pool들은 일반적으로 물리적 메모리의 많은 부분(large fraction) 을 모든 process의 kernel address space로 map 한다.
ASLR
memroy corruption 버그들은 종종 특정 data 의 주소들의 지식을 요구한다. memory corruption bug 들을 이용한 공격들을 지연시키기 위해서 non-executable stacks 와 stack canaries 가 와 함께 address space layout randomization(ASLR) 이 소개됐다.- non-executable stacks
- stack canaries
- address space layout randomization(ASLR)
kernel 을 보호하기 위해 KASLR 은 모든 boot 에서 드라이버가 위치하는 곳에 대한 offset들을 randomize 한다. kernel data 구조의 위치를 추측하게 만들기 때문에 결과적으로 공격을 하기 어렵게 한다.
side-channel attack
그러나 side-channel attack 들은 kernel data 구조들의 특정 위치를 알 수 있게 해주거나 자바스크립트에서 ASLR 을 무력화 시킨다. 소프트웨어의 버그와 이 주소들의 지식은 높은 권한의 코드 수행을 가능하게 해준다.Cache attack
보통 CPU 들은 cache 를 가지고 있다. 우리가 거의 상식적으로 알고 있듯이 cache 는 자주쓰는 내용을 저장해 놓고, 빠르게 불러오는 용도의 저장소라고 할 수 있다.Address space translation tables 들도 memory 에 저장되면서 동시에 regular cache 들에 cached 된다.
Cache side-channel attacks 은 cache 들로 인해 생기는 시간차(timing differences)를 이용한다.
예제, toy example
아래의 코드를 보자.raise_exception(); // the line below is never reached access(probe_array[data * 4096]);
이 코드에서
access(probe_array[data * 4096]); 부분은 실제로 수행될 수 없다. 일단은 앞에 raise_exception() 에서 프로그램이 종료되기 때문이기도 하고, raise_exception() 이 없다고 해도 이부분은 OS 에서 exception 으로 처리해서 이론적으로는 접근할 수 없다.그런데, out-of-order exception 때문에 CPU 는 아마 이미 위의 코드에 해당하는 모든 instruction 들을 수행했을 것이다. 왜냐하면, exception 코드와
access(probe_array[data * 4096]); 코드는 dependency 가 없기 때문이다.이것은 register 나 memory 로 load 되지 않았기 때문에 크게 문제되지 않지만, 미세구조적인 부작용(microarchitectural side effect)이 있다.
out-of-order execution 를 수행하는 동안에 참조되어지는 memory 는 register 에 fetch 되고, 또한 cache 에 저장된다. 만약 out-of-order execution 이 버려져야 하면, register 와 memory 에 있는 내용들은 commit 되지 않는다. 그럼에도, cached 된 내용은 cache 에 그냥 남아 있게 된다.
Flush+Reload 로 "특정 memory 위치가 cache 됐는지 여부"를 알아낼 수 있는데, 이 방법을 통해 이 microarchitectural side-channel attack 의 효과를 크게 할 수 있다.
access(probe_array[data * 4096]); 는 probe_array를 data 값에 따라 4096 byte(4kB) 간격으로 접근하게 된다. 그래서 data 의 값으로 부터 memory page 까지의 injective mapping 이 있다. 즉 2개의 값은 같은 page 로 접근이 되지 않는다. 결과적으로 만약 page의 cache line 이 cached 되면 우리는 data 의 값을 알 수 있다.(역자: 이것에 대한 좀 더 이해하기 쉬운 설명은 ref. 3을 확인하자. ref. 3 의 설명은 data 의 값은 cache된다 하더라도 user 가 접근할 수 없기에, data 을 주소를 가리키는 index 로서 사용해서 data 가 array 의 어떤 부분을 가리키는지를 확인하므로써 data 의 값을 판단한다고 한다.)
prefetcher는 page 범위들을 넘어서 data 를 접근할 수 없기 때문에, 다른 페이지들로 펼치는 것은 prefetcher 에 의한 false positive (틀렸는데 맞다고 하는 경우)들을 없애준다.
Meltdown
Meltdown(멜트다운) 은 2개의 빌딩 블럭들을 합쳐 놓은 것이다.
먼저 공격자는 CPU 가 transient instruction sequence(일시적으로 머무르는 명령어 순서) 를 실행하게 한다. 이 transient instruction sequence는 물리적인 메모리 어딘가에 저장해 놓은 "접근할 수 없는 비밀 값(inaccessible secret value)" 을 사용한다.
transient instruction sequence 은 은신처의 송신기처럼 동작해서 결국에 공격자에게 이 비밀값을 넘겨주게 된다.
Meltdown 은 3가지 단계로 구성된다.
Step 1
공격자가 접근할 수 없는 특정 메모리 위치의 내용이 register 로 load 된다.원래 user application 의 virtual address 에도 kernel memory 의 내용이 mapping 된다. 그러나 user 의 권한으로 이 부분을 접근하면, OS 는 exception 을 발생시킨다.
여기서 meltdown 은 out-of-order execution 취약점을 이용한다.
Step 2
transient instruction 은 register 의 비밀내용을 바탕으로 cache line 에 접근한다.Step 3
공격자는 Flush와 Reload 를 이용해서 자신이 접근할 cache line을 정할 수 있게 된다. 그래서 결국 선택된 메모리 위치에 저장된 비밀을 접근할 수 있게 된다.여러 메모리 위치(memory location) 에 대해 이 방법을 반복해서 사용하므로써 공격자는 물리적인 메모리 전체와 kernel memory 를 dump 할 수 있다.
See Also
References
[컴] 플래시 메모리 SLC, MLC, TLC
간단한 정리 SLC, MLC, TLC / 플레쉬 / 플래쉬 / nand flash / 메모리 /
erase
간단한 flash memory 동작
쓰고, 지우기
셀에 전자를 채워넣고, 채워진 전자를 빼내는 방식을 하는 것이 우리가 흔히 아는 write, erase 가 된다.
읽기
- 채워진 전자의 양에 따라 자기장의 크기가 달라지는데, 이것에 의해 그 밑을 지나는 N 채널의 전도폭이 변한다.
- 이 N채널의 전도폭의 차이로 인해 전하량에(전류값에) 차이가 발생
- 이 전하량을 읽어서 어디부터 어디까지는 0으로, 어느값부터 어느값까지는 1로 구분한다.
SLC, MLC, TLC 의 cell
SLC 는 cell 하나에 2의 state 만 표현하는 것이다. 즉 전자가 채워져
있으면 1로 보고, 비워져 있으면 0으로 보면 된다.
MLC 는 cell 하나에 전자가 채워진 양에 따라 4가자의 state 를 표현하게
된다. 전자가 1/3 정도 채워지면 01, 2/3 정도 채워지면 10, 3/3 채워지면
11, 비워져 있으면 00 으로 보게 된다.
TLC 는 cell 하나에서 8가지 state 를 표현한다. MLC 와 마찬 가지로 1/7
정도 채워져 있으면 001, 2/7 정도 채워져 있으면 010, … 그래서 7/7 차면,
111 이 된다.
ECC 코드
위에서 한 이야기 처럼 SLC 보다 MLC, TLC 는 전자를 세밀하게 조절해야
한다. 그래야 하나의 cell 에서 여러가지를 표현할 수 있다. 그런데 이렇게
세밀하게 조절하면 필연적으로 간섭이 발생한다. 그래서 MLC, TLC 들은
확실히 SLC 보다 error 가 많다. 그래서 이 에러를 줄이기 위해 ECC(Error
correcting code) 를 크게 줄 수 밖에 없다. 그래서 MLC, TLC 가 SLC 의 2배
용량이 되지 못하고, 성능도 좋지 못한 이유다.
산화막
cell 에 전자를 가두고, 흘려버리기 위해 산화막을 사용하는데, 이 녀석을
전자가 계속 왔다갔다 하다 보면 전자가 이 산화막에 조금씩 쌓이게 된다.
(대충 철에 자력이 걸려서 철이 자석이 되는 것을 상상하면 된다.)
이렇게 되면 이 산화막을 통과하는 양이 줄어들거나 할 텐데, SLC 는
state 간의 전압차가 커서 어느정도 전하량이 줄어들어도 인식하는데 큰
문제가 없지만, MLC 나 TLC 는 state 간의 전압차가 크지 않아서 전압이
미세하게 틀어져도 잘못된 값으로 write / erase 될 수 있다.
그래서 MLC, TLC 의 수명이 SLC 에 비해 떨어진다.그래서 이것을 극복하기 위해 spare 영역, over provisioning 부분을 추가해 놓는다.

적층구조
위 그림 설명의 GATE 가 최초에는 ‘floating gate’ 라는 이름으로 ’도체’를 사용했다. 그래서 그 안으로 (-)전자를 끌어드렸다. 이 도체 floating gate의 상태가 변하고 1, 0 을 표시하게 된다. 위 그림의 스위치 on/off 를 보면 될 것 같다.
SLC 는 이것을 채우고 비우는 것으로 1, 0 을 표시하는 것이고, MLC 는 이 floating gate 가 비어있으면 00, 1/3정도 채운것을 01, 2/3 채우면, 10, 3/3 을 채우면 11 이 된다.
그런데 공정이 미세해지면서 cell 간의 간섭을 줄이기 위해 ’부도체’로 바꿨다. ’부도체’는 말그대로 ’전자’가 흐르지 않는다. 그래서 구멍(trap)이 많은 부도체(실리콘 나이트라이드)를 이용해서 그 구멍에 전하를 저장하게 한다. (치즈를 연상하면 된다.)
![from : [플래시메모리, 어디까지 알고 있니] 플래시메모리 No.1 역사의 시작 | 삼성반도체](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEhesiTW1kGe_KFsiyrP_9GjD1AiJxRccxVYMKXI4SvwypK_cgd776Ol3dOLW24cXnWlhzlpmn8n2X0a4oAJr2wXTXkCPZBtRsNgLOLHbQ6y1onq8u0mha4JR4CX8HBYeIwK46WYps_igawR8SVg_Cxtl6xWhc7JkZDXdCl00ADZCGEngvD-fn0/s0/all-there-is-to-know-about-flash-memory-how-no1-flash-memory-came-about_PC_3.webp)
![[그림.2] from: https://www.samsungsemiconstory.com/m/434](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEjsMaDmLLIIP1HLSi6no6rAx2WP8UUi-2TtSWv1dUN5-EKXpLOMxSymb_FDO8-5Y-DQcgQrLNy5dR8ilV62d4TXv-1N40XC4swqTYdFuv-klQqoHbDJJbmbqO7PWsTzVKNJp1PBrg/w640-h414/image.png)
이제 이것을 세로로 세운다. 위 그림(그림. 2)과 아래 그림(그림. 3)을
참고하자. 이렇게 세워서 양쪽으로 이 것을 붙이는 구조를 만들었다. 이것이
‘3D V-NAND’ 이다. 이렇게 양쪽으로 붙이게 되면서 이것을 원형으로 만들어
사용하게 됐다. 그림2 그림을 보면 짐작이 가지만 이것이 요즘
’구멍’을 얼마나 더 깊게 뚫을 수 있느냐를 이야기하는 것의 핵심일 것이다.
이 구멍을 뚫어야 control gate 안에 반도체와
Floating Gate 를 집어넣을 수 있을테니 말이다.
[K-반도체, 도전과 응전] ①누가 한국 반도체산업을 위협하나 - 오피니언뉴스 낸드 플래시 기술의 핵심은 저장공간을 높게 쌓은 뒤 전류가 흐르는 구멍(hole)을 한 번에 뚫는 ‘싱글스택(Single stack)’ 기술이다. 삼성전자는 128단 낸드플래시에도 싱글스택을 적용했다. SK하이닉스는 128단 최초 양산시 더블 스택을 적용했다. 100층 빌딩을 지을 때 한 번에 쌓아 올리기 않고 50층씩 두개를 연이어 쌓은 셈이다. 싱글스택은 더블스택보다 회로가 간단해 속도가 빠르다. 생산공정도 간단하다. 성능은 높은데 생산비용은 덜 드는 것이다.
포브스는 마이크론의 176단 낸드 출시를 전하면서 “마이크론 관계자가 176단 낸드가 88단을 두번 쌓은 ’더블스택’이라고 언급했다”고 밝혔다. 영미권 전자 전문지 아난드테크(anandtech), 익스트림 테크(Extreme Tech), 퍼드질라(fudzilla) 등은 모두 마이크론 사의 176단 낸드플래시가 “88단을 두번 쌓은 제품”이라고 분석하며 “새로운 기술이 아니다”고 덧붙였다.

References
[컴] 비트코인의 hash 알고리즘
비트코인 해쉬 알고리즘 / 해시 알고리즘 / bitcoin hash funciton
Bitcoin
비트코인관련 흥미로운 글이 있어서 정리 해 놓는다.-
Bitcoin 에서 사용하는 hash function 은 SHA-256 이다.
- Bitcoin 은 security 를 위해 SHA-256 을 두번 사용한다.(double-SHA-256)
- 어떤 hash 값을 찾느냐 하면, 연속된 0 으로 된 hash 값을 찾아야 한다.
- hash function 은 원래 예측안되는 random 값을 결과로 주며, 역으로 추측할 수 없는 특성때문에 특정 hash 값을 찾으려면 원하는 hash 값이 나올때까지 input 을 계속 변경하는 수밖에 없다.
- 현재(2017년 12월)는 연속된 0이 약 17개 정도 있는 hash 값을 발견해야 한다. 이것의 확률은 1/140,000,000,000,000,000,000 정도라고 한다.
- 비트코인 블럭 샘플
- hash function 의 input 으로 주면 연속된 0 을 가진 hash값(block hash) 가 나오게 된다.
- hash input 은 아래 값들을 모아서 만들어진다.
- version
- previous block hash(reversed)
- Merkle root(reversed)
- timestamp
- bits
- nonce
- 비트코인 블럭 샘플의 값을 가지고 테스트 해보면 이미 채굴된 값이라서 당연히 연속된 0이 나오지만, 대부분의 경우는 그렇지 않다. 그 경우에는 nonce 나 다른 부분의 값을 변경하면서 연속된 0 이 나오는 input 을 찾아야 한다.
SHA-256 해쉬 알고리즘
- SHA256 hash algorithm 은 512bits 를 input 으로 받는다.
- 그래서 결과로 256-bit 을 내어준다.
- SHA 256 은 간단한 작업을 64번 반복해서 output 을 만든다.
- 이 간단한 작업을 그림으로 표현하면 아래와 같다.
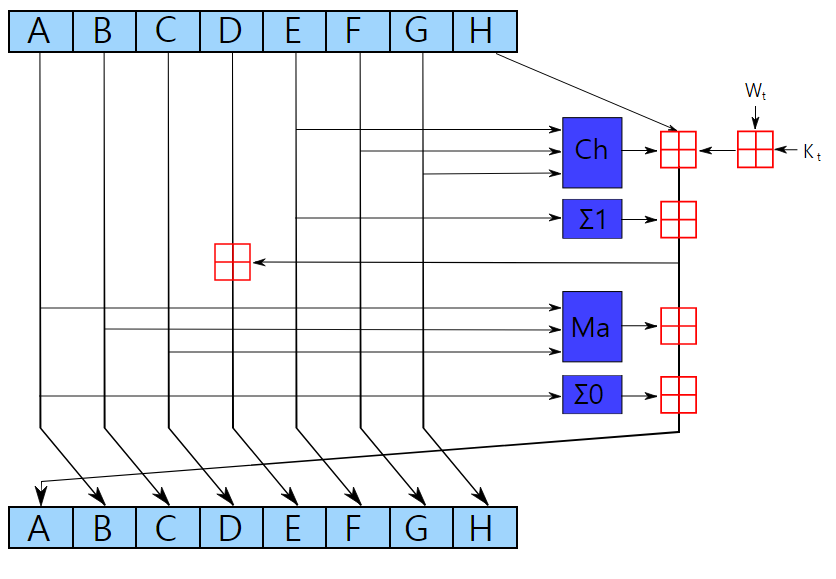
{kind=link}
1 round
잘보면 대충 알 수 있는데, 일단 A,B,C,D,E,F,G,H 는 각 하나당 4byte(32bit) 로서 총 64 byte를 보여준다. 한 round 를 수행하면, ABCDEFG 가 오른쪽으로 움직이고, H 만 여러가지 계산을 거쳐서 A의 자리로 가게 된다. 자세한 설명은 아래 링크들을 참고하자.scrypt hash algorithm
- 하드웨어로 구현이 어렵도록 디자인된 hash algorithm
- Litecoin / Dogecoin 등의 가상화폐가 사용한다.
[컴] https 패킷 캡쳐하기
Wireshark 에서 https 패킷 decrypt 하기
chrome/firefox 에서 SSLKEYLOGFILE에 key log 들을 저장해 준다. 그래서 이것을 이용해서 wireshark (1.6 이상 버전)에서 https packet을 decrypt할 수 있다.[ref. 1]SSLKEYLOGFILE 변수지정
- 먼저 SSLKEYLOGFILE 변수를 지정하자
- 그리고 firefox/chrome을 restart 하자.
- 그리고 https request 를 하면
- 지정한 곳에 log 가 만들어지는 것을 확인할 수 있다.
제어판 > 시스템 > 고급시스템 설정 > 환경변수 > 새로만들기
- SSLKEYLOGFILE=c:\a\sslkeylog.log
 |
| 그림에는 철자가 틀렸다 |
Wireshark 에서 설정(Preference)으로 가자.
- preferences > Protocol > SSL > (Pre)-Master-Secret log filename 에 c:\a\sslkeylog.log


References
- NSS Key Log Format - Mozilla | MDN
- Decrypting TLS Browser Traffic With Wireshark – The Easy Way! | Jim Shaver
- CertSimple | Wireshark 2 is the simplest way to inspect HTTPS on your Mac
[컴] ffmpeg 으로 video container 변경
ffmpeg 으로 video container 변경
FFmpeg download for windows
아래경로에서 ffmpeg 의 binary 를 다운로드 할 수 있다. 보통 .zip 으로 되어 있다. 이 안에 bin folder 에 ffmpeg.exe 가 있다.
video file 에서 transcoding 없이 container 만 변경할 때
03.mkv 를 03-01.mp4 로 변경하는 명령어이다. -c copy 를 하면 mkv 의 내용을 그냥 그대로 mp4 로 copy 한다.(transcoding 없이)c:\..> ffmpeg.exe -i 03.mkv -c copy 03-01.mp4
다른 기능들
ref. 2 를 보면 아래와 같은 내용을 확인할 수 있다.- 1. Cut video file into a smaller clip
- 2. Split a video into multiple parts
- 3. Convert video from one format to another
- 4. Join (concatenate) video files
- 5. Mute a video (Remove the audio component)
- 6. Extract the audio from video
- 7. Convert a video into animated GIF
- 8. Extract image frames from a video
- 9. Convert Video into Images
- 10. Merge an audio and video file
- 11. Resize a video
- 12. Create video slideshow from images
- 13. Add a poster image to audio
- 14. Convert a single image into a video
- 15. Add subtitles to a movie
- 16. Crop an audio file
- 17. Change the audio volume
- 18. Rotate a video
- 19. Speed up or Slow down the video
- 20. Speed up or Slow down the audio
References
[컴][LLVM] Visual Studio 에서 Clang tool 빌드 하기
Clang 의 AST 이용하기
c:\> clang hello.c를 하면, a.exe 를 만들어 낸다. 우리는 이런 실행파일을 원하는 것은 아니다. clang 내부에서 쓰는 AST 자료를 사용할 것이다.
source code 가 있다면 CLang 이 preprocessor 를 실행해서 이 source code 를 parse 해서 AST(Abstract Syntax Tree) 를 만든다.[ref. 1]
이 AST 를 얻기위해서 아래처럼 하면 AST 를 console 에 뿌려준다.
c:\> clang -Xclang -ast-dump -fsyntax-only hello.c
이 AST 를 이용해서 source code 를 다루는 이유는 source code 자체에 대한 분석이 용이하기 때문이다. AST 를 보면 대략 알겠지만, 각 code 가 어떤 의미를 갖는지에 대한 정보를 다 만들어준다.(예를 들면, 함수인지 여부, 변수인지 여부 등등)
The Clang AST
- Introduction to the Clang AST — Clang 5 documentation
- Introduction to the Clang AST — Clang 5 documentation > Examining the AST
CLang interface
CLang 에서 AST 를 이용할 수 있게 3가지 interface 를 제공하는데, "CLang 문서" 에서 대해 말해준다.- LibClang : 대부분 Clang 을 쓴다면 이녀석을 사용하게 될 것이라고 한다. 다른 Clang 의 interface 는 LibClang 을 쓰지 말아야할 이유가 있을 경우에 사용하라고 한다.
참고로 LibClang 은 AST 의 full control 을 제공하지 않는다. - Clang Plugins : compile 할 때 만드는 AST 에 어떤 추가적인 작업을 넣고 싶을 때 이 interface 를 사용하면 된다.
- LibTooling : C++ interface 이다. ref. 1 에서는 이 LibTooling 이 처음에 사용하기에 가장 적합하다고 이야기한다.
개인적으로는 ref. 1 의 설명이 더 이해하기 좋다.
Visual Studio 에서 Clang tool 만들기
일단 위의 글(ref. 3)의 code 를 가지고 작업을 해보자.Visual Studio project file 만들기
source 와 CMakeLists 만들기
아래처럼 구조를 만든다. 여기서 아마도 반드시 폴더 이름을 extra 로 해야할 것이다.<llvm>\tools\clang\tools\extra + CMakeLists.txt + \loop-convert + CMakeLists.txt + LoopConvert.cpp
<llvm>\tools\clang\tools\CMakeLists.txt 에 아래와 같은 code 가 기본으로 들어가기 때문이다.
add_llvm_external_project(clang-tools-extra extra)
<llvm>\tools\clang\tools\extra\CMakeLists.txt
add_subdirectory(loop-convert)
<llvm>\tools\clang\tools\extra\loop-convert\CMakeLists.txt
set(LLVM_LINK_COMPONENTS support) add_clang_executable(loop-convert LoopConvert.cpp ) target_link_libraries(loop-convert clangTooling clangBasic clangASTMatchers )
<llvm>\tools\clang\tools\extra\loop-convert\LoopConvert.cpp
// Declares clang::SyntaxOnlyAction.
#include "clang/Frontend/FrontendActions.h"
#include "clang/Tooling/CommonOptionsParser.h"
#include "clang/Tooling/Tooling.h"
// Declares llvm::cl::extrahelp.
#include "llvm/Support/CommandLine.h"
using namespace clang::tooling;
using namespace llvm;
// Apply a custom category to all command-line options so that they are the
// only ones displayed.
static llvm::cl::OptionCategory MyToolCategory("my-tool options");
// CommonOptionsParser declares HelpMessage with a description of the common
// command-line options related to the compilation database and input files.
// It's nice to have this help message in all tools.
static cl::extrahelp CommonHelp(CommonOptionsParser::HelpMessage);
// A help message for this specific tool can be added afterwards.
static cl::extrahelp MoreHelp("\nMore help text...");
int main(int argc, const char **argv) {
CommonOptionsParser OptionsParser(argc, argv, MyToolCategory);
ClangTool Tool(OptionsParser.getCompilations(),
OptionsParser.getSourcePathList());
return Tool.run(newFrontendActionFactory<clang::SyntaxOnlyAction>().get());
}
cmake-gui.exe
이 상황에서 linux 의 경우는 CMake 를 하면 될 것인데, VS 에서는 일단 필자는 cmake-gui.exe 를 이용했기 때문에, .proj 만 하나 따로 생성 하는 법을 모른다. ^^;;; 그래서 모든 .proj 를 다시 만드는 법을 택했다.(참고-LLVM 을 Windows Visual Studio Community 2015에서 build)대신에 기존의 path 이름을 임시로 변경해 놓고 -> 새롭게 만들고 -> 필요한 부분만 옮겨놓고 -> 이름을 바꾸는 방식을 택했다.
그렇게 얻고나서 필요한 부분만 기존의 .sln/.proj 있는 곳을 copy 해주면 된다. 그러니까 여기서는 아래 부분이 되겠다. 아래 그림에서 왼쪽패널이 새롭게 만든것이고, 오른쪽으로 copy 한 것이다.
- <llvm>\build\tools\clang\tools\extra\

project 추가
이렇게 하고, 다시 .sln 이 있는 곳의 folder 이름을 변경해 주고, LLVM.sln 을 열었다. 그리고 나서 아래처럼 solution explorer 에서 project 를 add 해주면 된다.
exe 위치
loop-convert 의 build 가 끝나면 아래 위치에서 exe 를 확인할 수 있다.- <llvm>\build\Debug\bin\loop-convert.exe
exe실행
f:\>c:\a\programming\llvm\llvm\build\Debug\bin\loop-convert.exe test.cpp --이러면 test.cpp 를 분석해준다.
뒤에 "--" 표시는 "--" 뒤에 오는 "compiler 에 대한 추가적인 옵션"들을 사용해라. 라는 뜻이다. 즉 위의 경우는 아무런 옵션도 사용하지 않겠다는 뜻이 된다.
"--" 가 없는 경우에 compiler option 을 compilation database 에서 가져오게 된다.
이방법을 이용해서 ref. 2 의 예제를 한번 따라해 보면 될 듯 하다. 참고로 ref, 2 의 소스코드는 옛버전의 llvm 소스를 바탕으로 해서, 몇가지 수정해야 돌아간다.
References
- Clang Tutorial Part I: Introduction | Bits, Bytes, Boos
- Clang Tutorial Part II: LibTooling Example | Bits, Bytes, Boos
- Tutorial for building tools using LibTooling and LibASTMatchers — Clang 5 documentation
피드 구독하기:
글 (Atom)