cors 설정 / redirect fetch / fetch cors
web 에서 B site 에서 A server 로 fetch 를 보내고, B로 redirect 를 받은 경우
- 다음 sequence diagram 은 만약 내가
site.a.com에 접속한 상황에서 fetch 로api.a.com에 request 를 했다. 그 상황에서api.a.com가 redirectsite.a.com를 나에게 던져준 경우이다. - 이 경우 예상치 못하게 cors error 가 떴다.
site.a.com
--> fetch api.a.com
--> redirect to site.a.comCORS error 가 뜨는 이유
CORS error 가 뜨는 이유는 Origin 이 site.a.com 이 아니라 null 로 set 돼서 site.a.com 로 request 를 보내기 때문이다. 그렇게 되면, browser 에서 orgin 과 서버가 보낸 Access-Control-Allow-Origin 값을 비교할 때 두 값이 달라서 error 를 던지게 된다.(아래 Fetch: Cross-Origin Requests 부분 참고)
- 여기를 보면, 처음 request 를 보낸 url에서 바뀐적이 있으면, redirect-tainted origin 으로 본다. 그렇기에 Origin 이 null 로 잡힌다.
- 이러면 origin 이 ‘null’ 로 바뀌었다고 봐야 하기 때문에
site.a.com에서 CORS 를 지원하기 위한 설정을 잡아줘야 한다.
CORS error 가 없이 동작할 때
다음처럼 api.a.com 으로 보내고 api.a.com 으로 redirect 되는 경우는 다음처럼 CORS error 가 안뜨고, 잘 동작한다.
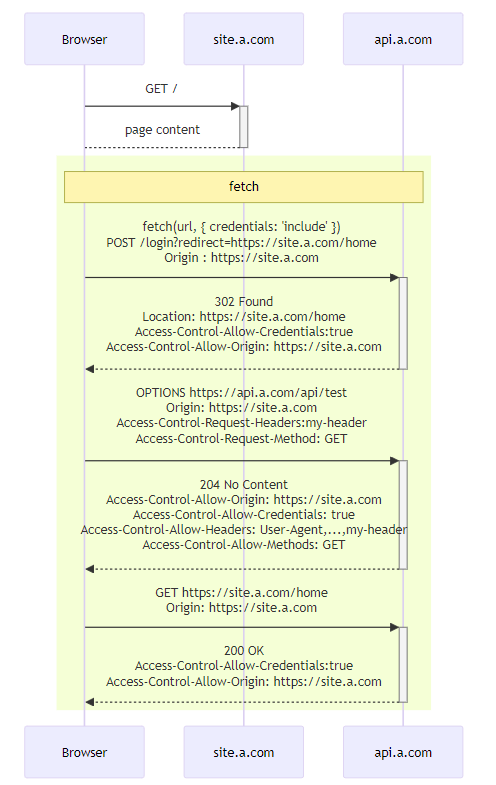
CORS error 가 안뜨게 수정
- 아래는 이때 CORS error 가 뜨지 않도록 header 를 맞춰준 예시이다.
조정한 내용:
Accee-Control-Allow-Origin: nullAccess-Control-Allow-Credentials: trueAccess-Control-Allow-Headers에Access-Control-Request-Headers에서 요청한 header를 넣어준다.Access-Control-Allow-Methods를Access-Control-Request-Method에 맞춰서 지정
api.a.com 으로 보내고 site.a.com 으로 redirect 되는 경우 : mermaid link

fetch 를 사용할 때 redirect :
- python - How to redirect the user to another page after login using JavaScript Fetch API? - Stack Overflow
fetch 를 한 후 redirection 을 응답으로 받는 경우
예를 들어,
http://a.com/api/a로 request 를 보낸 경우, redirect 로http://a.com/api/b가 오는 경우는 한 번 fetch 를 보내면, redirected request 까지 알아서 수행된다.redirect 가 cors policy 에 걸리는 경우라면, error 를 내보낸다.
const resp = await fetch(realUrl, fetchParam) consoel.log(resp.redirected) // true consoel.log(resp.url) // http://a.com/api/b` - Cannot get next URL for redirect="manual" · Issue #763 · whatwg/fetch · GitHub
fetch(url, {redirect: 'manual'})을 사용하는 경우, redirect response header 의 Location 을 알 수 있는 방법이 없다.- javascript - redirect after a fetch post call - Stack Overflow 의 댓글들
CORS error 가 안뜨게 하려면
CORS error 가 안뜨게 하려면, 다음처럼 설정을 하면 된다.
client :
- `credentials : ‘omit’
mode : 'no-cors'
server :
Access-Control-Allowed-Origin: *Access-Control-Allow-Credentials: false
Fetch: Cross-Origin Requests
- client 에서
Origin을 보내면, 그것을 server가 본다. - server 는 그에 따라
Access-Control-Allow-Origin을 만들어서 response 에 보낸다. - browser 가 trusted mediator(신뢰할 수 있는 중재자) 역할을 한다. 즉, browser가 이제 client 에서 보냈던 origin 이랑 서버가 보낸
Access-Control-Allow-Origin값을 비교해서 값이 적절하면, javascript 가 response 값을 access 할 수 있게 해준다.
javascript 가 기본적으로 접근할 수 있는 safe header 는 다음과 같다.
- Cache-Control
- Content-Language
- Content-Length
- Content-Type
- Expires
- Last-Modified
- Pragma
js 가 다른 header 에 접근하고 싶어도 browser가 접근을 막는다. 다만 server 에서 Access-Control-Expose-Headers 에 추가된 header는 browser가 js 한테 열어준다.
이제는 browser가 안전하지 않은 요청(unsafe request)는 바로 날리지 않는다. preflight request 를 먼저 날리고 나서 날리게 된다.
- Access-Control-Request-Method : 어떤 method 로 보내려는지 적는다.
- Access-Control-Request-Headers : 보내려는 request 가 갖고 있는 header들을 적는다.
- Origin : request 가 어디서 보내는 request 인지를 적게 된다.
200 OK
Content-Type:text/html; charset=UTF-8
Content-Length: 12345
Content-Encoding: gzip
API-Key: 2c9de507f2c54aa1
Access-Control-Allow-Origin: https://javascript.info
Access-Control-Expose-Headers: Content-Encoding,API-Key서버단에서 redirect 시켜서 CORS 피하기
- preflight 등의 성능을 방해하는 요소를 줄일 수 있다.
- 참고:
┌─► http://localhost:8081
http://localhost:8080 │ ┌─────────────┐
│ │ │
http://localhost:8080/api──┘ │ WAS │
┌─────────────┐ │ │
│ web server │ │ │
│ ┌───────┤ │ │
│ │ │ └─────────────┘
│ │ asset │
│ │ │
└─────┴───────┘