kafka 특징
ref.1 에 대한 번역 및 정리
- Kafka 는 data stream 들에 적응하는 real-time streaming data pipeline 과 real-time streaming application 들을 만들때 사용한다.
- Kafka 는 다음의 것들을 묶는다. 그래서 historical data 와 real-time data 에 대한 저장(storage)과 분석(analysis)이 가능해 진다.
- messaging
- storage
- stream processing
- data pipeline : 신뢰할 수 있게 data 를 처리하고 한 시스템에서 다른 시스템으로 이동시킨다.
- streaming application : data 의 stream 을 사용하는 application 이다.
웹사이트의 사용자의 행동 데이터를 실시간(real-time) 으로 처리하는 data pipeline 이 있다면, kafka(카프카)는 다음 2개를 동시에 제공할 수 있다.
- streaming data 를 소화하고(ingest) 저장 하면서
- data pipeline 에 동력을 공급하는 application 에게 read 를 제공
Kafka 는 또한 message broker solution 으로도 이용되기도 한다.
message broker solution: 2개의 application 간에 통신을 처리하고, 중재하는 플랫폼이다.
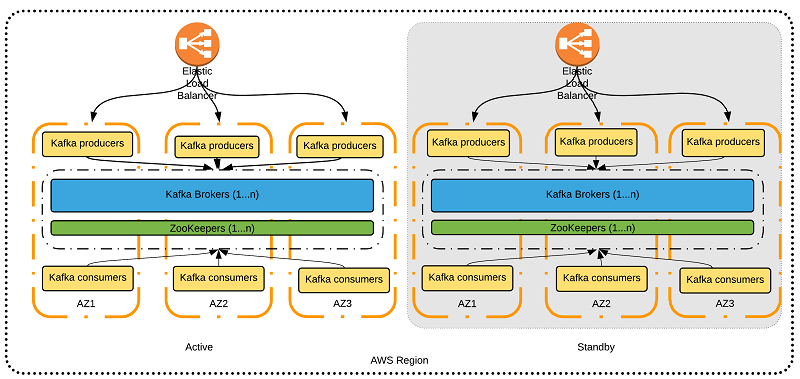 |
| from: see also. 1 |
zookeeper:
- kafka는 cluster state 와 cluster cofiguration을 관리하기 위해 zookeeper 를 사용한다. zookeeper 없이는 kafka 를 clustering 으로 구성할 수 없다. 심지어, 1개의 kafka 를 사용할 때도 zookeeper가 같이 설치돼야 동작한다. 요즘 새버전은 이 zookeeper없이 clustering 을 가능하도록 변하고 있다.
- What is ZooKeeper & How Does it Support Kafka? - Dattell
kafka 동작
Kafka 는 각 model 의 주요 이점을 사용자에게 제공하기 위해서 다음 2개의 messaging model 을 결합했다.
- queueing
- publish-subscribe
기존 queue, publish-subscribe 의 문제
- 기존의 queue 는 multi-subscriber(하나의 queue 에서 하나의 message 를 여러명이 가져가는 구조) 가 되지 않았다.
- 기존의 publish-subscribe 은 모두 subscriber 에게 같은 message 를 뿌리는데 그래서 work 를 여러 worker process 로 분산시키는 작업은 안됐다.
partitioned log model
그래서 kafka 가 partitioned log model 을 사용해서 이 solution 들을 묶었다.
kafka는 “record들을 다른 topic 들에게 publishing 하는 방법”(by publishing records to different topics) 으로 2개의 다른 model의 문제점을 개선한다. 각 consumer 는 topic 안에 있는 partition 에 할당된다. 이것이 data 의 순서를 유지하는 동시에 multi-subscribers 를 가능하게 해준다.
- log 는 record 들의 ordered sequence (정렬된 순서)이다.
- 이 log 들은 다른 subscriber 들에 대응되는 segment 또는 partition 으로 쪼개서 넣어질 수 있다.
- 같은 topic 에 대해서 여럿의 subscriber 들이 있을 수 있고,
- 각 topic 은 더 높은 수준의 scalability 를 가능하게 하기위해 partition 에 할당된다.
- 이 partition 들은 여러 서버에 분산되어지고, 복제되어진다.
- 이것이 높은 확장성, fault-tolerance, 병령성(parallellism)을 가능하게 해준다.
- kafka 의 model 은 replayability 를 제공한다.
- application 마다 독립적으로 read 가능: data stream 에서 read 하는 여러 독립적인 application 들이 독립적으로 그들의 속도로 일할 수 있게 해준다.
partitioned log
- 각 topic 은 partitioned log 를 갖는다.
- 이 partitioned log 는 구조화된 commit log 이다.
- 이 commit log 는 모든 record 들을 순서대로 추적하고 실시간으로 새로운 record 를 append 한다.
 |
| kafka broker 는 kafka server 를 이야기 한다. (참고) |
kafka 사용시 이점
- scalable : partitioned log model 이라서 여러 서버에 data 를 분산시켜 저장할 수 있다. 그래서 한개의 서버를 넘어서는 확장이 가능하다.
- fast : data stream 과 분리되어 있다. 그래서 latency 가 매우 낮기에 매우 빠르다.
- durable : partition 들은 여러서버에 분산되어지고, 복제되어 있다.(replicated) 그리고 모든 data 들은 disk 에 써져있다. 이것이 server failure 를 막아준다. data를 매우 fault tolerant 하고 durable 하게 해준다.
storage system 처럼 동작
- Kafka는 또한 모든 데이터를 디스크에 쓰고 복제하기에 확장성과 fault-tolerance가 뛰어난 storage system 처럼 동작힌다.
- Kafka 는 disk space를 다 쓸때(run out of)까지는 data를 disk 에 보관한다.
- 하지만 user가 retention limit (정체 한도)을 정할 수 있다.
kafka가 제공하는 4개의 api
- Producer API: Kafka topic 으로 “records 의 stream” 을 publish 하기 위해 사용된다.
- Consumer API: topic들에 subscribe 하고 그들의 “records 의 stream” 을 처리하기 위해 사용한다.
- Streams API: applications 이 stream processors 처럼 행동하는 것을 가능하게 한다.
- stream processor : topic(s)으로 부터 input stream을 받아 다른 topic(s)로 가는 output stream 로 변환해서 보낸다.(me: 한 topic 에서 data 를 받아서 그것을 다른 topic 으로 넘겨주는 역할을 이야기하는 듯 하다.)
- Connector API: user 가 이 api 를 사용해서 현재 kafka topic들에 다른 application 또는 다른 data system 을 추가하는 것을, 중간에 끊김이 없이(seamlessly) 자동으로, 할 수 있다.
See Also
- Best Practices for Running Apache Kafka on AWS | AWS Big Data Blog
- Kafka 와 Confluent Schema Registry 를 사용한 스키마 관리 #1 | by Junghoon Song | Medium : message 를 전달할때 일정한 format (schema)을 맞춰서 보내고 받아야 하는데, 이 schema 를 dynamic 하게 변경할 수 있게 해주는 Schema Registry 를 소개한다. GraphQL 과 비슷한 concept 이라고 보면 될 듯 하다.
- LINE에서 Kafka를 사용하는 방법 - 1편 - LINE ENGINEERING: line 에서 "데이터 허브"로 kafka 를 사용한다. 가혹한 작업 부하(work load)에서 보호하는 방법으로 request quota 를 조절하는 것이 중요하다고 한다.
- Apache Kafka(카프카)의 특징 및 모델
- 쿠...sal: [컴] kafka 설치하기
댓글 없음:
댓글 쓰기